365Explorer Release: A Browser-Based PowerShell Tool for Microsoft 365 Security Investigations
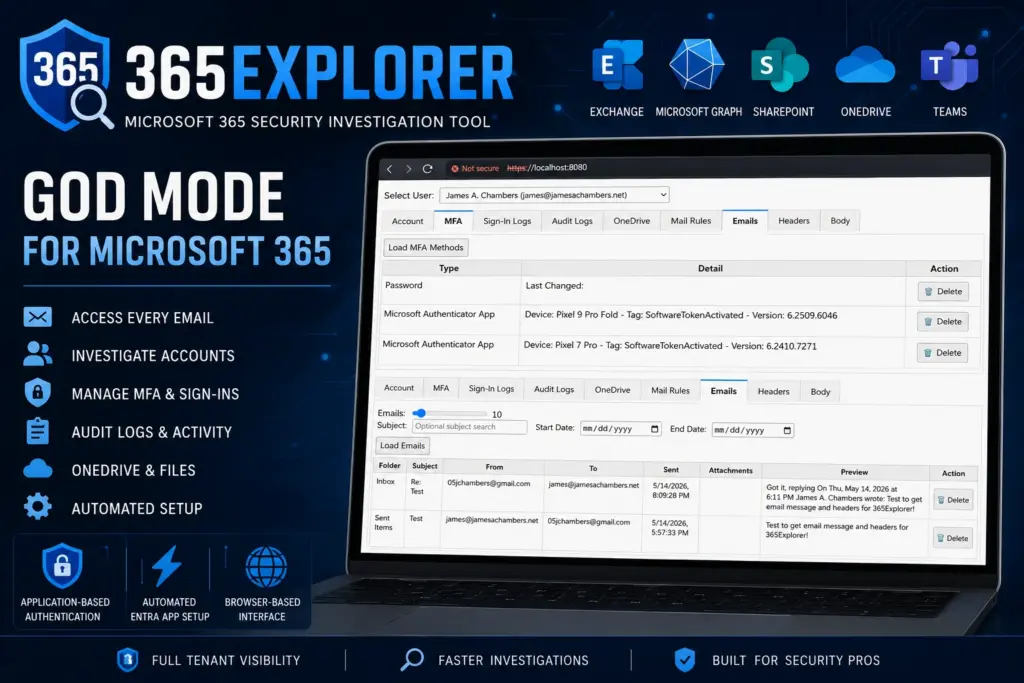
365Explorer is now available as a PowerShell module designed to make Microsoft 365 security investigations faster, simpler, and far less painful than the usual Entra admin workflow. It runs a local web server and gives you a browser-based interface that feels closer to a security console than a traditional PowerShell script.
At its core, 365Explorer is built around application-based authentication using Microsoft Graph and Exchange Online, giving administrators a level of access that normally takes a lot of manual setup or higher-tier licensing to achieve.